本文所述为计算机组成原理课拓展实验的相关记录,基于“龙芯体系结构与CPU设计教学实验系统” 项目官网: http://www.loongson.cn/business/general/teach/356.html; 相关资料代码:#TODO:: github仓库 PS:标题可简记为《基于基于的一种基于的一种实现》
🤓吐槽时间
快考试了,👴发觉👴计组学了个🔨,👴去年也学了个🔨,但是去年可以归因于晦气的晦气,今年只能说自己晦气。难道还要重蹈去年的晦气吗?👴本应该回去背课本,刷考研题,但是👴一看ppt就想起我们敬爱的《计算机组成原理》课的任课老师,丐哥反复强调的至理名言:“听不懂的举手(无停顿)都没举手,都听懂了,非常好。”本人十分钦佩丐哥老师对幽默感的独特理解。
(但是特此声明:本人不了解、不认同其关于"5G是个几把",“高晓松很nb这个人”,“钱=浪漫"等议题的看法)
而且👴这人很怪,课本上的重点,不好玩;选做的实验,好玩!哎就是玩,怪不得卷不过别人,你也配卷?滚去考研吧。
众所周知,计算机学生的本科生涯,如果能做到在自己设计的CPU上运行自己写的操作系统并用自己写的编译器跑代码,那就非常成功了。👴差不多,👴能在自己搜的代码上写自己的注释并用自己的电脑截图,都是三个"自己”。那么今天给大家爆个啥捏,流水线奥。
🔧 “用”计算机→“造”计算机
上回书说到(#TODO:: CSAPP大篇),汇编器(as)让我们得到了机器能看懂的比特流,最后一步只需要连接器(ld)将其和其他调用一起载入内存。这回答了程序如何在CPU这个平台上运行的问题,然而一个更基本的问题是,这个现有的平台是如何实现的?一个粗略的认识是,我们知道这些足以实现CPU的复杂的逻辑,其最小单元总对应到简单的诸如逻辑门上面,但是落实到真正的物理实现之上,如何使效率最高?功耗最小?这些问题所跨越的复杂度的量级依然是一片巨大的迷雾。照亮这片迷雾的知识,大概隶属于IC学科。
However,作为CS专业而不是IC专业,我们的目标仅在于理解所谓“组成原理”。在IC产业的复杂度规模数轴上,向下是专有芯片(又称嵌入式?),功能专用,规模较小;向上是通用芯片,即手机电脑等的核心,其难度不言而喻。位于中间的FPGA则既兼顾了自由度也考虑了速度,因此,这玩意能满足CS本科教学的需要(主要是便宜耐操)。
🔮高贵的IC工程师都用啥轮子
Vivado是一个FPGA集成设计平台(也算一个EDA?),他主界面左侧的工作流窗口很好的概括了利用FPGA开发的基本流程。即
- 编写设计源码(Source):使用Verilog语言编写逻辑或引入IP
- 设计仿真模拟(Simulation):通过观察仿真波形图和编写testbench来对设计进行debug
- 综合(Systhesis)门级网表:从RTL级描述降维到门级网表
- 生成(Implementation)布局布线:根据管脚约束,将依然是虚拟的门级连线落实为实际的线路
- 进行硬件编程(program):生成比特流并写入目标设备
- 生成(Implementation)布局布线:根据管脚约束,将依然是虚拟的门级连线落实为实际的线路
- 综合(Systhesis)门级网表:从RTL级描述降维到门级网表
- 设计仿真模拟(Simulation):通过观察仿真波形图和编写testbench来对设计进行debug

名词解释: IC:集成电路 FPGA:现场可编程门阵列 Verilog:一种硬件描述语言,语法涵盖了自顶向下五个抽象层面:系统级、算法级、RTL级、门级、开关级。 RTL:寄存器传输级。一般使用最多的就是RTL级。 IP:Intellectual Property内核模块,可以理解为将代码封装为函数。分为,软IP内核(soft IP core),固IP内核(firm IP core)和硬IP内核(hard IP core)3个层次,相当于集成电路的毛坯、半成品和成品。 SoC:片上系统,大概是芯片及其装载的第一层软件接口的集合,很宽泛的概念。 EDA:电子设计自动化。
由此,我们可以大致探清了这片迷雾,CPU的设计如何从高抽象层次的逻辑,梳理成最底层的逻辑门,再实现为小小的芯片。那么我们有了轮子,要造一个CPU,还要确定目标指令集。由于本项目由龙芯公司赞助,那必然要选MIPS了。
📌MIPS指令集格式
啥叫指令集呢,学过几种语言就不难理解。高级程序语言规定每个ascii码的组合所对应的含义,指令集规定0和1的组合所对应的寄存器,ALU的各种信号。MIPS指令集从属于RISC系列,最基本的指令有31条。
//讲到这里本应该打个表展示31条指令,但是👴懒得打了。
Vivado中,.coe文件用于初始化IP核,本实验给出的.coe文件中存放了几条指令,不过是16进制数字,写个小脚本打印成可读的形式。
|
|
打印出来👴傻了,怎么还有不在31条范围里的。
|
|
总之,代码都给你了,下面给出一个vivado实验的完整流程,不全面,但是都是踩坑经验。
🆒Vivado使用
本流程环境:Vivado 2020.2
开发板型号:LS-CPU-EXB-1
创建项目
下一步,下一步,下一步,,,确认。 这一步只需要注意选器件,一定要选对。否则有可能在Implementation遇到“端口电平不匹配”“端口数量不足”等硬件问题。当然,有可能型号相近的性能规格也差不多,这属于玄学问题了。实验书上选择的的型号应该是“xc7a200tfbg676-2”,但是👴用的是“xc7a200tfbv676-2”也能成功写入比特流。
编写代码并仿真
本实验的代码大多来自“2016-04-14”,那就是龙芯公司给的源代码。在该系列代码中有一处bug,位于“单周期CPU实验”的single_cycle_cpu.v中。214行,resetn应该为{4{resetn}},写使能位宽应为为4。

下面讲解一下项目结构,所有实验都是类似的:
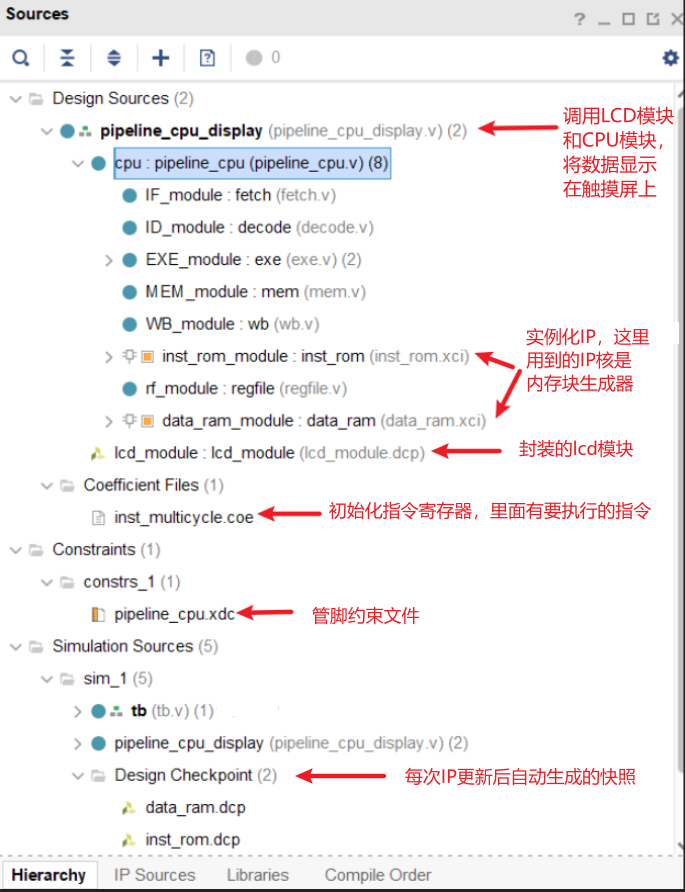 三个顶层文件夹分别对应Add Source里的三类源文件:添加设计,添加仿真,添加约束。如果不需要上板,只完成仿真,那么只需要添加设计(几个.v),添加仿真(testbench.v/tb.v)就足够了,xxx_display.v也是上板需要的故而可以忽略。(实际上,图中我用箭头标记的都用不到)。
三个顶层文件夹分别对应Add Source里的三类源文件:添加设计,添加仿真,添加约束。如果不需要上板,只完成仿真,那么只需要添加设计(几个.v),添加仿真(testbench.v/tb.v)就足够了,xxx_display.v也是上板需要的故而可以忽略。(实际上,图中我用箭头标记的都用不到)。
编写tb,无非是给tb里声明为input的信号赋值,还可以使用#xx,让tb等待一段时间。
点击Run Simulation,等一会就能看到波形图。波形图有三种颜色:
- 绿色代表信号正常正常;
- 红色的X代表信号不确定;
- 蓝色的Z代表信号休眠。
一般遇到红X,都是未初始化问题。蓝Z大概是没有模块调用这些信号。Vivado波形图的操作极其难用,这里介绍一个相对好用的操作:左键从左向右水平划,会直接缩放到鼠标滑过的这一段。右键选择进制等操作略。
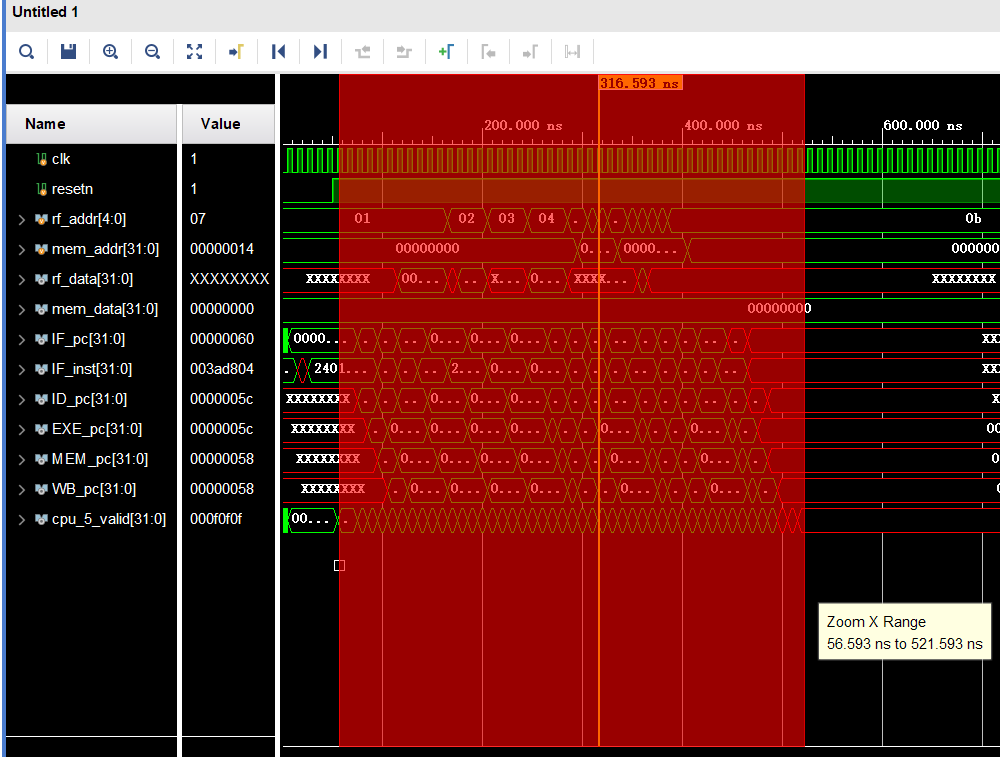
仿真需要注意的问题:
- 如果文件没问题,模块调用层次会被自动解析从而呈现成一棵树,而不是好几个顶层文件。
- 注意set as top,应该设为根部模块(调用其他模块的)和tb
- //如果设错了可能在Implementation会出现“端口未赋初值”的报错。
- 中文乱码是经典字符集问题,有可能在换行处导致语法错误。建议统一换成utf-8。
- 简单解决方法:从vscode里复制。
引入IP核
对于流水线CPU,data_ram和inst_rom需要同步写,自己实现比较复杂,故直接实例化封装好的内存块IP。如何引入?首先说明几种文件格式:
- .dcp 原意为checkpoints文件,是一种加密压缩文件。用于封装模块方便调用,但对版本要求极其敏感。
- .xci/.xcix IP核配置文件,本质是一个xml。是Vivado在新版本提倡使用xci而不是dcp。
- .xdc 管脚约束文件。在Implementation用到,此处按下不表。
这几种文件格式都是可以直接Add Source添加进来的。实验老师同时提供dcp和xci文件,添加dcp崩屎了,原因估计如上。添加xci之后,提示我将IP更新为core cointainer的形式
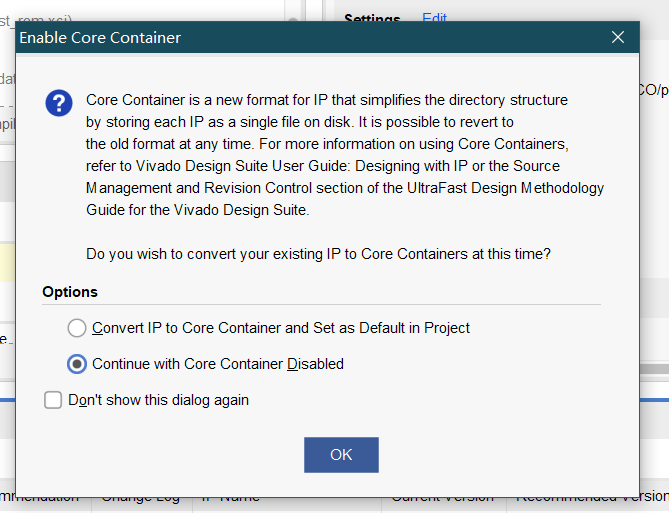
更新就完了。然后需要等一会,IP还要执行一步synth,这段时间里IP属于锁住的状态,不能修改配置。
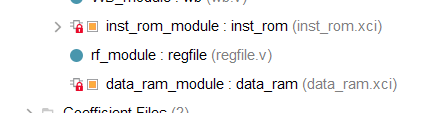
注意更换器件后,IP核都会锁住。这表示IP的配置和当前环境不匹配。对所有IP锁住的问题,只需要点击菜单栏Reports→Reports IP Status,然后点upgrade即可解除锁定。
我直接上板
直接点生成比特流,会一步步的按工作流向下运行,等待几分钟就能愉快的收获你的报错了!
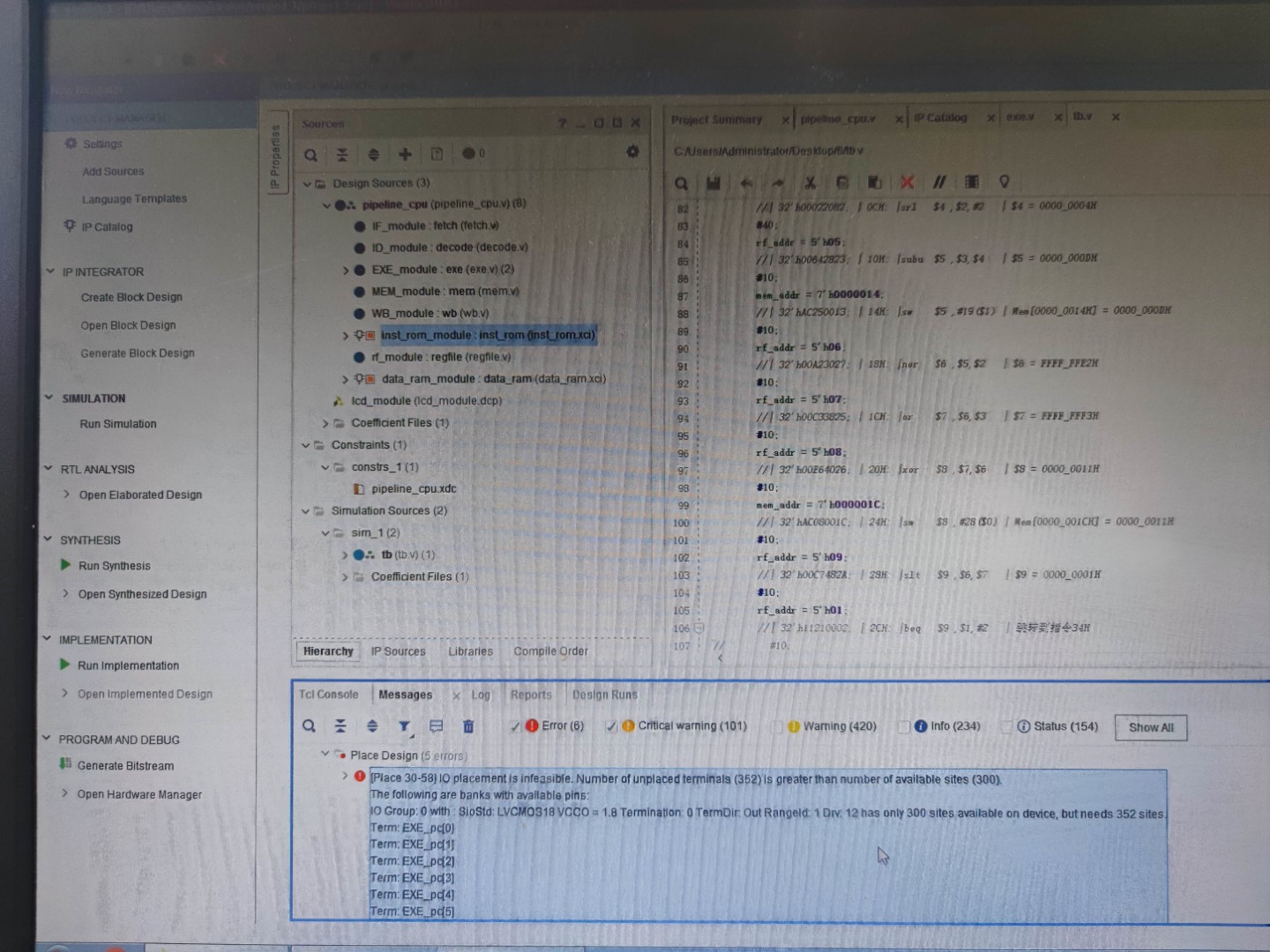
在把上文提到的坑都踩过一遍之后,终于没有critical warning,泪目。
但是此时实验课已经结束了,👴偷溜到没人的实验室,并留下以下珍贵画面

然后👴发现data_ram写入失败。但是👴没时间搞了,👴还是滚去复习课本吧。
🗿多周期流水线CPU原理
最后,继续复习计组。