手撕VM
虚拟内存(Virtual Memory)是现代操作系统的核心机制,而页表(Page Tables)是建立虚拟内存的基础设施。本实验学习xv6页表的生命周期并尝试修改,在实验前必须要阅读配套教科书《xv6: a simple, Unix-like teaching operating system (mit.edu)》第三章,其中讲述了VX6的三级页表机制及其实现。否则但从代码上难以入手。
理论:RISV-V三级页表
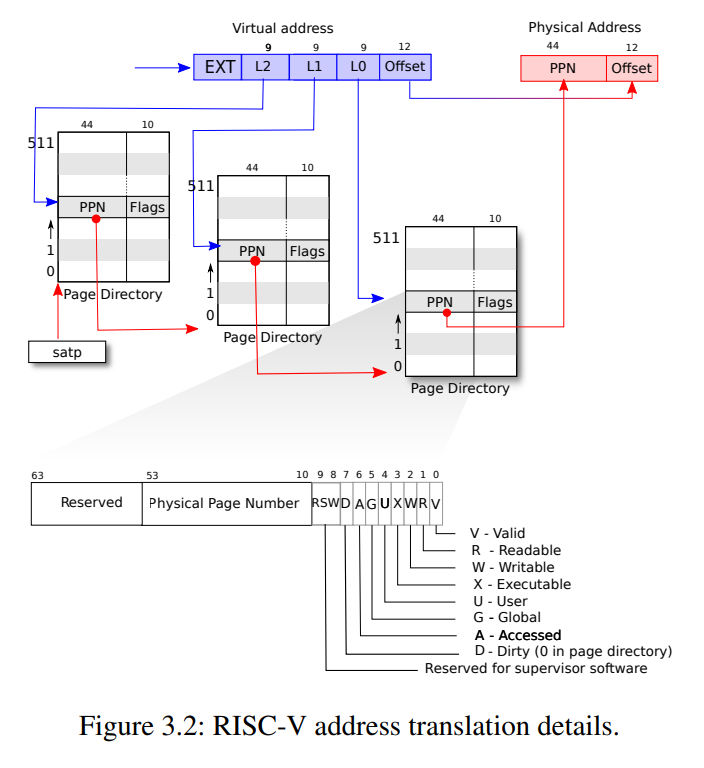
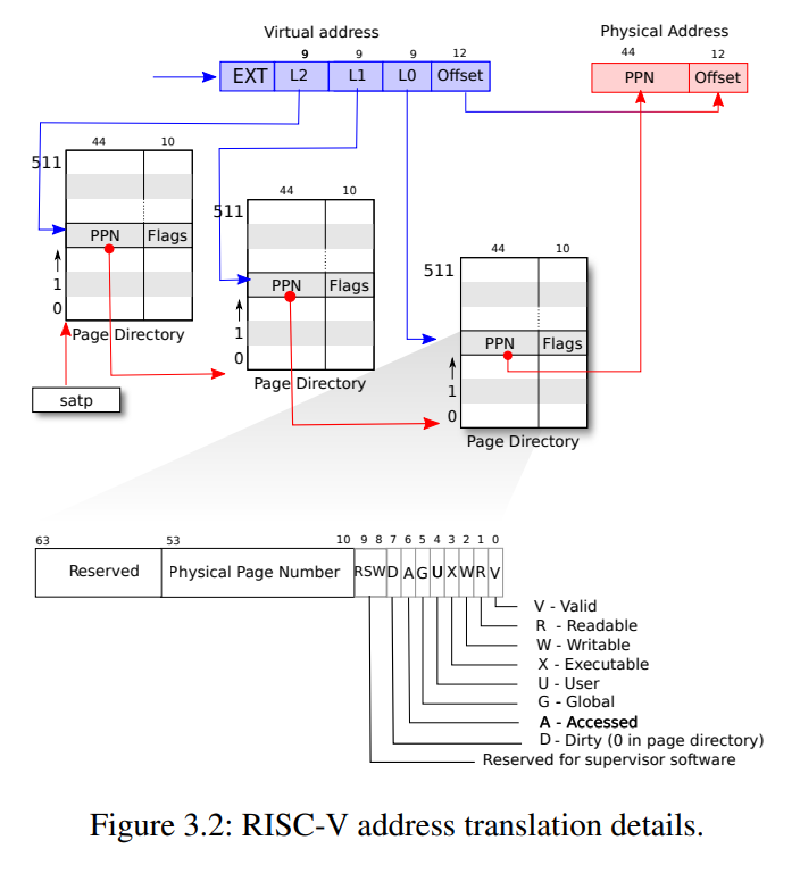
上图概括了XV6的地址翻译过程。下面是一些要点:
- 首先,XV6使用RISC-V的Sv39模式,即在64位地址长度中仅使用低39位作为虚拟内存。
- RISC-V中虚拟内存的布局方式由特权寄存器satp(Supervisor Address Translation and Protection)指定,还支持Sv48,Sv57,Sv64等模式。布局方式的选取通常是性能和可拓展性的权衡。
- 这39位虚拟内存被分割为三级页表索引(9+9+9)+12位页内偏移。
- 因此整个页表最多可包含2^27个页表项(PTE),每个分级页表长2^9=512。大小为64*512=4KB,正好是一个物理页的长度,即一个页表对应一个物理页。
- 每个PTE高10位保留,低10位存状态位,中间的44位存页号(PPN),根据状态位指示应该寻找下一级页表还是直接查询物理内存。
- 最后通过三级页表的跳转从39位虚拟内存翻译成44+12=56位物理地址。
- 最后的最后为避免晕头转向,复习一下分级页表的好处:降低整个页表的空间占用,通过TLB缓存加速访问。
以上内容在操作系统理论课中都大差不差的讲解过,而实验的重点是理解在XV6代码中这些理论如何变成现实。
实现:从上电开机开始
由于我们的实验是基于QEMU的,booting由QEMU完成,先按下不表。总之前面忘了,后面忘了,中间要准备好一个C代码的栈,以执行内核ELF。
所以直接进入内核c代码的起点kernel/main.c:
|
|
- 首先,
kernel/kalloc.c:kinit()用于初始化物理内存分配器。 - 随后执行的
kernel/vm.c:kvminit()初始化内核页表。内核态只需管理一个内核页表,相对简单,大部分情况进行直接映射。 kernel/vm.c:kvminithart():为了开启虚拟内存,内核必须为CPU设置好satp,包括上文提到的Sv39模式以及根页表的物理地址。kernel/vm.c:procinit():初始化进程列表,并为每个进程分配了内核堆栈的地址。这是为了让每个进程都能独立的向内核态转换,我们向下追溯:
|
|
KSTACK宏来自kernel/memlayout.h,其中标记了XV6内存布局的常量:
|
|
- 可以看到
TRAMPOLINE位于虚拟地址最高位地址,是用户态和内核态共享的一个内存页。(至于这个页的作用后续实验会讲) - 紧随其后,映射的内核栈同时被一些保护页包裹,这是为了防止溢出干扰其他进程。利用权限机制,当溢出到保护页时内核会保护性崩溃。
- 除此之外还能看到 QEMU 模拟的物理内存地址开始于 0x80000000,停止到0x88000000,称为 PHYSTOP。那剩下那么多地址空间是干嘛用的?答案是预留给IO设备。由此可见虚拟内存的妙用,不论什么设备都能被映射到统一的地址空间。
内核态虚拟内存的建立到此结束,最后执行的userinit()建立了第一个用户态程序,其中的调用链为:
|
|
- 前面说到一个分级页表正好是一个物理页,因此创建页表的本质也就是kalloc()分配一个物理页。而后续向页表中添加新页的操作是由walk()完成的。
|
|
- walk()真正完成了三级地址寻址的逻辑,同时在寻址失败时还可以进行新页的创建,也就是一种运行时分配的策略。
至此,我们大致梳理了虚拟内存机制的建立,vm.c中还有许多API没有介绍,但还是让我们赶快进入正题吧。
lab3 PageTables
Lab3-1: Speed up system calls
上一个实验中我们梳理了系统调用的调用链,这一过程之所以这么复杂是因为涉及了内核态与用户态的转换。以getpid()为例,pid是内核中proc结构变量的成员,它存在于内核态页表中,用户态程序没有权限读取。因此需要系统调用getpid()在内核态中获取。这是一个只读的需求,却每次都需要进行完整的内核态切换,因此现代操作系统如linux通常利用VM机制来省略这一过程,让一块内核态的内存可以被用户态读取(当然只能读取),从而省下系统调用的开销。
实验指引中已为我们定义好了相关数据结构:
kernel/memlayout.h:内存布局中预留的页:
|
|
user/ulib.c:用户态调用方式:
|
|
定义有了接下来看怎么操作。实验指引同时提醒我们仿照trapframe来处理内存页USYSCALL的生命周期。那么就在代码中搜索一下trapframe,主要在proc.c,包括4个函数:
allocproc():初始化进程,分配物理内存页proc_pagetable():为进程分配页表- 注意使用
PTE_R | PTE_U权限位,除了可读还要设置特权级为用户态。
- 注意使用
freeproc():销毁进程数据结构proc_freepagetable():清理页表
照葫芦画瓢复制一遍即可,别忘了为proc结构体添加成员变量。
Extra: 还有哪些系统调用可用此方式加速?
不涉及内存分配的应该都可以,比如uptime,内存页USYSCALL足够放很多数据,只需要添加赋值的逻辑即可。
Lab3-2: Print a page table
在vm.c中定义函数void vmprint(pagetable_t pagetable) 用来打印页表。该函数插桩在kernel/exec.c:exec()的最后。
实验指引我们仿照freewalk()来递归遍历页表。只需将其中free的逻辑改为打印的逻辑即可。
这里给出一个递归版实现,实际上就三层循环不递归也可:
|
|
这个题没有打分脚本,看着输出差不多就行。
Lab3-3: Detect which pages have been accessed
大的来了,实现pgaccess()系统调用,检测被访问的页。实验指引说的云里雾里我们不管,直接看从评分脚本开始看代码:user/pgtbltest.c
|
|
可以看到,int pgaccess(void *base, int len, void *mask);接受三个参数,分别是检测对象(起始地址),检测长度(页数),检测结果(以掩码的格式)。掩码对应位置置1表示该页面已访问,掩码用uint格式,故len的上限是64。
那么用什么数据结构存储已访问信息呢,还是回到本文首图,可以看到PTE中第6位就是用来干这个的,代码中用PTE_A标记。其赋值CPU已经处理好,只需要考虑读取即可。
实验指引还提供了这些hints:
- 系统调用的注册都已写好,直接进入
kernel/sysproc.c来实现sys_pgaccess()。解析参数等相关API请复习Lab2。 walk(pt, va)输入页表和虚拟地址,返回对应的最后一级PTE。- 我们需要的结果需在内核态计算,用
copyout()转储到用户态。 PTE_A每次使用完必须清除,否则污染下一次调用的结果。- 活用
vmprint()来调试。
代码量其实不多,难点在于理解如何获取连续虚拟地址对应的内存页。 我们知道,当malloc()分配了一块连续的内存,其物理物理分布大概率也连续但也可以不连续。不过这一切都由页表完成,我们只需要使用walk()函数这一va到pa的封装。因此只需要从base开始遍历执行walk()即可。
|
|
Lab3-E: Extra:
Super-pages
使用 super-pages 来减少页表中的 PTE 数量。一个 super-page 大小4M而不是4K。
- 👴找了半天没找到 RISC-V super-pages 的相关文档,遂作罢。
Null pointer
取消映射用户进程的第一个页面,这样在引用空指针时就会出现故障。您必须修改 user.ld,使用户text.段从 4096 开始,而不是从 0 开始。
- 一开始愣是没看懂啥意思。还是得回到内存布局中,text段是最低地址也就是从0开始的。因此当引用空指针时,指向的是text段中的0地址,就不会报错,留下安全隐患。
- 因此需要把整个内存布局往后挪。首先修改
user.ld
|
|
- 然后修改
kernel/proc.c:userinit()中的p->trapframe->epc = 0; - 和
kernel/vm.c:uvmfirst()中的mappages(pagetable, 0, PGSIZE, (uint64)mem, PTE_W|PTE_R|PTE_X|PTE_U);然后就报错了。那咋办嘛,调试呗。然而调不利索,等我学完后面的必秒此题。
Dirty page
添加一个系统调用,该调用使用 PTE_D 报告脏页。
- 和Lab3-3大同小异
打个分⑧
usertests耗时好几分钟,还以为报错了,其实是正常现象。